
Overview
 To the
right is a picture of the entire Clutch software stack for a
typical MapReduce application. The Java Virtual Machine (JVM)
is, of course, at the very bottom of the stack. Clutch itself
is built on top of ProActive/Remote Method Invocation, which
provide the capability to make method calls on remote objects
transparently. MapReduce-
"a programming model and an associated implementation for
processing and generating large data sets" - is then
implemented using Clutch agents. Finally, the end user
developer's application is implemented on top of the Clutch
implementation of MapReduce. Because all of the communication
details are handled by Clutch and all of the MapReduce
bookkeeping has already been implemented, the end user
developer need only worry about implementing a few simple
classes in order to accomplish the task at hand.
To the
right is a picture of the entire Clutch software stack for a
typical MapReduce application. The Java Virtual Machine (JVM)
is, of course, at the very bottom of the stack. Clutch itself
is built on top of ProActive/Remote Method Invocation, which
provide the capability to make method calls on remote objects
transparently. MapReduce-
"a programming model and an associated implementation for
processing and generating large data sets" - is then
implemented using Clutch agents. Finally, the end user
developer's application is implemented on top of the Clutch
implementation of MapReduce. Because all of the communication
details are handled by Clutch and all of the MapReduce
bookkeeping has already been implemented, the end user
developer need only worry about implementing a few simple
classes in order to accomplish the task at hand.
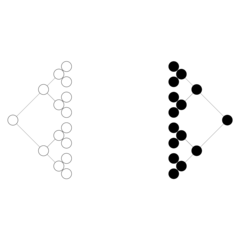 The
double-tree to the left is the intended overall organization of
a system of Clutch agents. Using a few simple organizational
rules, the agents attempt to organize themselves in this manner
using only local information. In other words, there is no
global scheduler or specialized organizing agent that tells new
agents "where to go" within the system. Agents that end up in
the leftmost tree take on the role of "mappers", while agents
that find themselves in the right side of the tree are
"reducers". (More information on these two types of
computational roles can be found in Google's paper on MapReduce ).
In addition, each agent maintains one or more links to the
"other side" of the double-tree (not pictured) in order to
propagate data from left-to-right; in other words, raw data is
processed by mappers, propagated to one or more reducers for
further processing, and eventually finds its way to the root of
the reduce side of the tree where final results are written to
disk to be collected by the user. More on the implementational
details later.
The
double-tree to the left is the intended overall organization of
a system of Clutch agents. Using a few simple organizational
rules, the agents attempt to organize themselves in this manner
using only local information. In other words, there is no
global scheduler or specialized organizing agent that tells new
agents "where to go" within the system. Agents that end up in
the leftmost tree take on the role of "mappers", while agents
that find themselves in the right side of the tree are
"reducers". (More information on these two types of
computational roles can be found in Google's paper on MapReduce ).
In addition, each agent maintains one or more links to the
"other side" of the double-tree (not pictured) in order to
propagate data from left-to-right; in other words, raw data is
processed by mappers, propagated to one or more reducers for
further processing, and eventually finds its way to the root of
the reduce side of the tree where final results are written to
disk to be collected by the user. More on the implementational
details later.
A simple example
In order to implement any Clutch application, three basic components are needed:
- a MapTaskFactorythat describes how to generate a MapTaskfrom raw input
- a MapTaskimplementation that can map raw input (provided by the MapTaskFactory) to a set of key-value pairs
- a ReduceTaskimplementation that can reduce sets of intermediate key-value pairs (i.e., output from a previous MapTaskor ReduceTask) to sets of result key-value pairs
One example of a simple Clutch application is one that computes the frequency of unique words in a file. The MapTaskFactoryfor such an application would take the following form:
public WCMapTaskFactory() {}
public MapTask createMapTask()
throws IOException
{
WCMapTask task = new WCMapTask();
...
// some code that reads data and generates a WCMapTask
...
task.addLengthOffsetPair(
new Pair<Long, Long>(offset, length));
task.setTotalLength(file.length());
return task;
}
public MapTask createMapTask(long offset, long length)
throws IOException
{
WCMapTask task = new WCMapTask();
...
// some code that reads data and generates a WCMapTask
...
task.addLengthOffsetPair(
new Pair<Long, Long>(offset, length));
task.setTotalLength(file.length());
return task;
}
}
Note that the class musthave an empty no-argument constructor. This is a constraint inherited from ProActive, the middleware layer used to build Clutch. It is also important to note that the MapTaskFactoryis responsible for generating length-offset pairs for the dataset as well as knowing what the total "length" of the dataset is. These lengths and offsets can be arbitrary - e.g., tasks could be assigned sequence numbers, with the total length being the highest number in the sequence - or they can be derived in some logical way, such as the total length of the file being read (as in the example above). These are strictly for bookkeeping and are the mechanism that Clutch uses to handle task re-execution and job completion.
The MapTaskin our example would look like the following:
public WCMapTask() {}
public ReduceTask map() {
WCReduceTask task = new WCReduceTask();
...
// some code that reduces the key-value pairs and populates
// the WCReduceTask with the result
...
return task;
}
}
The map()function is the only function that WCMapTaskmust implement. For our word frequency example, the map()function could generate a list of key-value pairs each of which had a word as the key and 1 as the value. The pairs would then need to get propagated to the ReduceTask being generated.
Finally, WCReduceTaskwould be structured as follows:
public WCReduceTask() {}
public void reduce() {
...
// some code that reduces intermediate key-value pairs
// into their "final" form
...
}
public List getResult() {
return resultList;
}
}
Coming soon: ReduceTask discussion, configuration, and code listings
More to do
Class diagrams, in-depth discussion of the design and implementation of Clutch, and a practical developer user's guide coming soon!